HardyPress Site Search is a way to deliver tailored search results to your site visitors. You can think of it as a replacement for the native WordPress full-text search, but fully compatible with your static site on HardyPress.
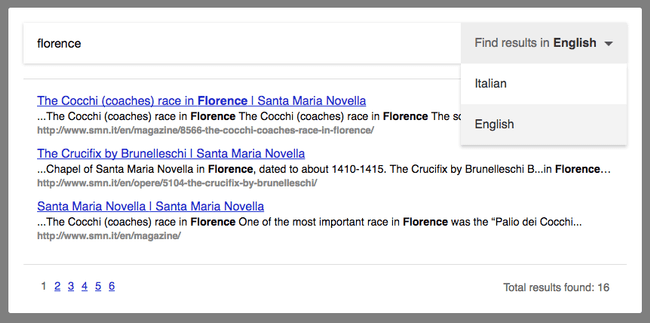
There are many third-party services out there that fill this need (SwiftType, Algolia, Cludo). Our solution seeks to be the best deal for the majority of websites:
- native integration with your website;
- completely customizable in terms of look & feel;
- works without the need to tweak any setting;
- handles nicely multi-lingual websites;
- included in the price of HardyPress with no additional charges.
How it works
- Everytime your website finishes being deployed, we’ll crawl it to fetch updated content;
- Crawling starts from the HomePage and recursively follows all the hyperlinks pointing to your domain. The time needed to finish the operation depends by the number of pages in your website and by yother factors, but normally we’ll do ~20 pages/sec;
- Through the HTML global
langattribute — or heuristics, if it’s missing — we detect the language every page was written in, so that indexing will happen with proper stemming. That is, if the visitor searches for “cats”, we’ll also return results for “cat”, “catlike”, “catty”, etc. - From your website, you can seamlessly use our native results modal box, or you can make AJAX requests to our JSON API to present relevant results to your visitors as your wishes.
Use our native results modal box
Our modal box is ready to be used in your theme that will probably include the WordPress native search form <?php get_search_form(); ?>
We will hook up to the submit event of the search form and will present results on a nice modal box that can be easily customized overriding the default CSS styles.
Manually integrating search on your site
If you prefer to customize the search-box behavior you can use our low-level API calls. First of all you need to obtain your site “slug”. You can find this information under the “Settings” tab on the HardyPress dashboard.
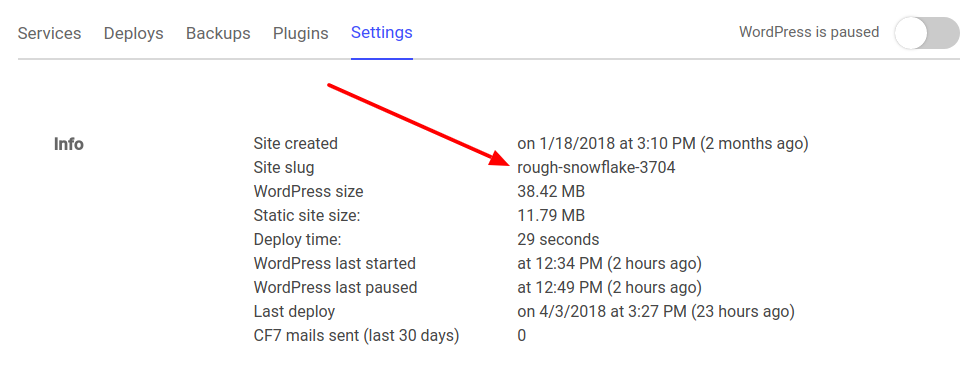
Than you can simple fire a GET request to our endpoint:
curl 'https://api.hardypress.com/rough-snowflake-3704/search-results?q=hello'You can also paginate results with the limit and offset query parameters:
curl 'https://api.hardypress.com/rough-snowflake-3704/search-results?q=hello&limit=2&offset=2'If you have a multi-language website, you can force to return only pages in a specific language with the locale option:
curl 'https://api.hardypress.com/rough-snowflake-3704/search-results?q=hello&locale=en'
If you have a multi-language website and you don’t pass any value for locale, HardyPress will try its best to return pertinent results inspecting the Accept-Language header of the request to find a matching language for the user visiting the page.
You can retrieve the list of indexed language with a GET request to the following endpoint:
curl 'https://api.hardypress.com/rough-snowflake-3704/search-result-locales'Exclude content from indexing
To give your users the best experience, it’s often useful to instruct HardyPress to exclude certain parts of your pages from indexing, for example website headers and footers. Those sections are repeated in every page, thus can only degrade your search results.
To do that, you can simply add a data-hardypress-noindex attribute to the HTML elements of your page you want to exclude: everything contained in those elements will be ignored during indexing.
<body>
<div class="header" data-hardypress-noindex>
...
</div>
<div class="main-content">
...
</div>
<div class="footer" data-hardypress-noindex>
...
</div>
</body>
The scraper bot will follow the rules of your site’s robots.txt file, so if you want to completely ignore a set of pages, you can target the HardyPressSearchBot agent:
User-Agent: HardyPressSearchBot
Disallow: /useless-stuff/
User-agent: *
Disallow: